 重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
 更多“如何以大肠杆菌质粒DNA为载体克隆一个编码动物激素的基因,并使之在大肠杆菌中进行表达?简要说明实验中可能”相关的问题
更多“如何以大肠杆菌质粒DNA为载体克隆一个编码动物激素的基因,并使之在大肠杆菌中进行表达?简要说明实验中可能”相关的问题
第1题
片段重新连接起来,得到如图Q25.1所示的结果。
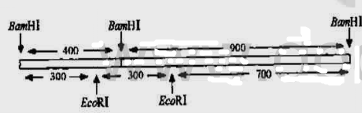 图025.1杂合基因的结构
图025.1杂合基因的结构
于是将这两种片段混合起来,并在连接酶的存在下进行温育,分别在30min和8h取样进行凝胶电泳分析。令人惊讶的是,连接产物并非是理想中的1.3kb的重组分子,而是一种复杂的片段模式[图Q25.2(a)]。同时发现随着温育时间的延长,较小片段的浓度逐渐降低,大片段的浓度逐渐增加。如果用BamH Ⅰ来切割连接后的混合物,则起始的片段可以重新产生[图Q25.2(a)]。
从凝胶中分离纯化出1.3kb的片段,并取出一部分用BamH Ⅰ进行切割,以检查它的结构。正如预料的一样,出现了两个原始的带[图Q25.2(b)]。但是用EcoR Ⅰ切割另一部分样品,希望能够产生两个300bp和一个长度为700bp的核苷酸片段,然而,凝胶电泳的结果,令人惊奇[图Q25.2(b)]。
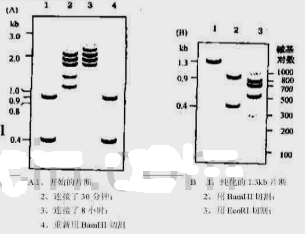 图Q25.2纯化DNA片段连接后电泳检测
图Q25.2纯化DNA片段连接后电泳检测
第2题
的基因表达中起作用。大核(巨核)含有细胞基因组的“工作”拷贝,由大量基因大小的双链DNA片段(微染色体)组成,它们活跃地进行着转录。含有核糖体RNA基因的微染色体拷贝数很多,可以用梯度离心进行分离。
在电子显微镜下检查,每一个核糖体微染色体是一种长为21kb的线性结构。进行凝胶电泳时,核糖体微染色体的迁移也是21kb(图025.3的第一泳道)。但是,如果用限制性内切核酸酶Bgl Ⅱ切割微染色体,产生的两个片段(13.4kb和3.8kb)的总和不等于21kb(图Q25.3的第二泳道),改用其他的限制性内切核酸酶切割,所产生的限制性片段的总和也都小于21kb,并且不同种酶切割产生的片段总和都不一样。如果把未经切割的微染色体先进行变性和复性处理,然后再进行凝胶电泳,所得到的双链DNA片段只有10.5kk)(图025.3第三泳道);与此相似的是,将Bgl Ⅱ切割的微染色体进行变性和复性,电泳后,13.4kb的片段被6.7kb的片段所取代(图025.3第四泳道)。

图Q25.3四膜虫核糖体微染色体限制性分析
数字指的是带的长度(kh)
请解释为什么限制性片段的总长度不等于21kb?为什么变性和复性之后电泳的结果有所改变?对于核糖体微染色体中的总序列组成你有什么看法?
第3题
涉及1.5×108以上的碱基对和几千个基因。在女性中,两条X染色体中的任何一条失活所造成的X连锁基因的表达与正常男性单个X染色体上基因表达的结果是相同的。虽然失活的机制仍不了解,一般认为失活作用是在染色体的特定区域,即X失活中心开始的,然后扩散到染色体的其他部分。虽然失活染色体上的大多数基因被关闭了,但少数仍有活性。因此,可以推测X的失活作用与X连锁基因的表达模式有关。为了验证这种推测,分离了大量的人的X染色体基因的cDNA并用Northern印迹法检查它们的表达。比较了这些基因在X染色体正常的男性和女性细胞中的表达、在X染色体异常的男性和女性个体中的表达,以及在啮齿动物:人细胞杂交株中的表达,这种杂交株保留了一个失活的人的X染色体(Xi)或是一个有活性的人X染色体(Xa)。

第4题
苷酸差异的手段。这种分析方法要使用成对的寡聚核苷酸:其中一个被生物素标记,另一个具有放射性标记或荧光标记。图Q25.5(b)的一对寡聚核苷酸是为了检测镰状细胞白血病[图Q25.5(a)]而设计的。
在分析过程中,分别将不同个体的DNA在有DNA连接酶的存在下,两两配对进行寡聚核苷酸杂交。将生物素酰化的寡聚核苷酸结合到固相支持物的抗生物素链霉蛋白上,然后通过放射自显影检查杂交结果,如图Q25.5(c)所示。

图Q25.5寡聚核苷酸连接分析(a)β-珠蛋白基因的β镰状细胞(βS)突变区的序列;(b)用于连接分忻的特异性的寡聚核苷酸;(c)βAβS之间单个碱基差异的检测分析,将生物素酰化的寡聚核苷酸收集在一个点,然后测定放射性
第5题
缺失。一对夫妇来进行遗传咨询,他们的第二个孩子出生后不久死于一种遗传性疾病,母亲又一次怀孕了。已夭折的孩子是家系中受此遗传病影响的第二例,另一例是孩子奶奶(父亲的妈妈)的一个兄弟。这对夫妇想知道这次所怀的孩子是否也有这种遗传病。你已经研究:过这种病的遗传性,并且知道是由常染色体的隐性基因所引起。在这种致病基因所处的染色体区内,发现整个人群中有几个限制性位点的多态性,如图Q25.6(a)所示,多态性用符号+/-表示。你分离了双亲、祖父母以及正常孩子的DNA样品,并用限制性图谱来分析它们的特性,结果示于图Q25.6(b)。现在开始检测胎儿,请预测什么样的限制酶切结果表明很可能具有遗传病?

图Q25.6携带有致病基因染色体的限制性图(a)来自不同家族成员的限制性模式,A、B、c表示多态性位点;(b)圆圈代表女性,方框代表男性,三角代表未出生的孩子
第6题
amH Ⅰ是5'突出端,Kpn Ⅰ则是突出的3'端(图Q25.7)。一位朋友建议用图Q25.7所示的寡聚核苷酸“片段”来进行连接。你并没有马上意识到这种方法可行,因为你想到的连接作用需要邻近的5'磷酸和3'羟基。虽然寡聚核苷酸分子被限制性内切核酸酶切割后会产生合适的末端,但是,合成的寡聚核苷酸的末端都是羟基。另外,虽然图Q25.7中接头是BamH Ⅰ-Kpn Ⅰ,但另一个接头却是Kpn Ⅰ-BamH Ⅰ。所以你怀疑相同的寡聚核苷酸是否能够适合这两种方式的连接。

图Q25.7用一种寡聚核苷酸片段连接不互补的限制性末端的图解
第7题
都能复制的质粒巧妙结合而成,它兼有病毒和质粒载体的优点。cDNA被插入载体的质粒部分,然后它能在体外被包装入病毒颗粒中,包装起来的载体感染大肠杆菌的效率比质粒本身要高得多。一旦进入了大肠杆菌,λYES中的质粒序列能够被诱导重组出基因组,并进行独立复制,这就可以从质粒中分离出来,以便进行进一步的遗传操作。
为了最大限度地提高克隆效率,载体用只有一个切点的限制性内切核酸酶Xho Ⅰ(5'-C↓TCGAG)进行切割,然后在dTTP存在的情况下,同DNA聚合酶一起进行温育。将一种具有平末端的双链cDNA同一段含由两段寡聚核苷酸组成的双链寡聚核苷酸接头连接起来,这两段寡聚核苷酸的序列是:5'-CGAGATTTACC和5'-GGTAAATC,它们的5'端都是磷酸。然后将载体和cDNA混合并连接在一起。采用这种方法用2μg的载体和0.1μg的cDNA,构建了一个有4×107个克隆的cDNA文库。问:
第8题
能的直接检测。免疫染色表明,这种蛋白质定位于细胞核内,如同推测的一样,是一种转录因子。如果能够测出它所结合的DNA序列,就可以从现有的序列资料中查找已知基因启动子的天然位点,从而能够找到它所调节的基因。
有人建议用PCR扩增同该蛋白质结合的微量DNA,思路是(图Q25.8):①合成一组长为26个碱基的随机序列的寡聚核苷酸混合体,在该序列的两侧各有一段25个碱基的序列作为PCR扩增的引物位点[图Q25.8(a)];②把这些寡聚核苷酸加到含有转录因子的细胞粗提取物中,转录因子可以同含有结合位点的寡聚核苷酸结合;③用转录因子特异的抗体分离同转录因子结合的寡聚核苷酸;④用PCR扩增选择到的寡聚核苷酸进行序列分析。

图Q25.8 用随机的寡聚核苷酸选择和扩增特异的DNA序列(a)用于选择的原初随机序列的寡聚核苷酸,N代表任何一种核苷酸;EcoR Ⅰ和BamH Ⅰ位点有利于选择DNA的克隆和序列分析。(b)同序列特异的DNA结合蛋白结合的寡聚核苷酸的选择和序列分析方案按照这一思路,用0.2ng单链随机序列的寡聚核苷酸开始了这项实验,这个寡聚核苷酸可以同一个PCR引物结合成部分双链,经过如图Q25.8(b)所示的四轮选择和复制后,用BamH Ⅰ和EcoR Ⅰ消化分离到的DNA,将片段克隆到质粒中,并测定了10个独立的克隆(表Q25.1),问:
表Q25.1 10个克隆的序列

注:画线的序列是PCR引物部位,两种序列都是从BamH Ⅰ末端开始,所有序列中结合位点的方向都是相同的。
第9题
因此计划将它从BamH Ⅰ的位点插入载体中。实验严格地按照克隆手册中的方法进行:载体用BamH Ⅰ切割以后,立即用碱性磷酸酶处理除去5'磷酸;接着将处理过的载体同用BamH Ⅰ切割的cDNA片段混合,加入DNA连接酶后进行温育,连接之后,将DNA同已处理过的可以接受DNA的细菌感受态细胞混合。最后,将混合物涂布在加有抗生素固体培养基的平板上。由于载体上带有抗生素的抗性基因,所以,转化的细菌能够存活。
实验中同时设置了四个对照:
对照1:将未同任何载体接触过的细菌细胞涂布在培养平板上。
对照2:将未切割载体转化过的细菌细胞涂布在培养平板上。
对照3:将经切割(但未用碱性磷酸酶处理)并用连接酶连接(但没有cDNA片段)的载体转化过的细菌细胞涂布在培养平板上。
对照4:将经切割(并用碱性磷酸酶处理过)并用DNA连接酶连接(但没有cDNA片段)的载体转化过的细菌细胞涂布在培养平板上。
在进行第一次实验时,感受态细胞不是自己制备的,结果在所有的平板上都长出了多到无法计数的菌落(表Q25.2)。在第二次实验中,自己制备感受态细胞,但这一次,所有的平板上都没有菌落生长(表Q25.2)。接着又进行了第三次实验,这次得到了转化子(表Q25.2)。从实验平板上挑出12个菌落,分离了质粒DNA,并用BamH Ⅰ进行切割,其中9个克隆产生大小同载体一样的单一的一条带,另三个克隆中切出一个cDNA片段,实验终于获得成功。
表Q25.2 cDNA克隆的结果
制备的样品 | 实验结果 | ||
1 | 2 | 3 | |
对照1 只有细胞 | TMTC | 0 | 0 |
对照2 未切的载体 | TMTC | 0 | >1000 |
对照3 省去磷酸酶处理,无cDNA | TMTC | 0 | 435 |
对照4 无cDNA | TMTC | 0 | 25 |
实验样品 | TMTC | 0 | 34 |
注:TMTC=too many to count,多到无法计数。
第10题
酸的短肽加到该蛋白质的N端或C端。这些带有组氨酸标签的蛋白质能够紧紧地同Ni2+柱结合,但很容易被EDTA或咪唑溶液洗脱。此法可以一步完成大量蛋白质的纯化。
图Q25.9是编码该蛋白质的核苷酸序列。请设计一对PCR引物,各含有18个同该基因同源的核苷酸,能够用于扩增该基因的编码序列。另外,在N端有一个起始密码,其后是6个组氨酸密码子。另设计一对引物,能够在C端加上6个组氨酸和一个终止密码。

图Q25.9欲修饰蛋白质的N端和C端的核苷酸序列
编码的氨基酸序列用一个字母标在下面。星号(*)代表终止密码。此图只标出了双链DNA上面的一条链
 客服
客服
 TOP
TOP

 警告:系统检测到您的账号存在安全风险
警告:系统检测到您的账号存在安全风险
为了保护您的账号安全,请在“上学吧”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!
































