 重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
设函数![设函数[图]在[图]上有定义,在[图]内任意插入[图]个分...设函数在上有定义,在内任意插入个分点](http://static.jiandati.com/650796d-chaoxing2016-751862.png) 在
在![设函数[图]在[图]上有定义,在[图]内任意插入[图]个分...设函数在上有定义,在内任意插入个分点](http://static.jiandati.com/d690f38-chaoxing2016-751863.png) 上有定义,在
上有定义,在![设函数[图]在[图]上有定义,在[图]内任意插入[图]个分...设函数在上有定义,在内任意插入个分点](http://static.jiandati.com/999b008-chaoxing2016-751864.png) 内任意插入
内任意插入![设函数[图]在[图]上有定义,在[图]内任意插入[图]个分...设函数在上有定义,在内任意插入个分点](http://static.jiandati.com/ef70b2b-chaoxing2016-751865.png) 个分点,
个分点,![设函数[图]在[图]上有定义,在[图]内任意插入[图]个分...设函数在上有定义,在内任意插入个分点](http://static.jiandati.com/39f83b6-chaoxing2016-751866.png) , 此分法记为
, 此分法记为![设函数[图]在[图]上有定义,在[图]内任意插入[图]个分...设函数在上有定义,在内任意插入个分点](http://static.jiandati.com/7474cef-chaoxing2016-751867.png) ,在每一部分区间
,在每一部分区间![设函数[图]在[图]上有定义,在[图]内任意插入[图]个分...设函数在上有定义,在内任意插入个分点](http://static.jiandati.com/438bc39-chaoxing2016-751868.png) 上取一点
上取一点![设函数[图]在[图]上有定义,在[图]内任意插入[图]个分...设函数在上有定义,在内任意插入个分点](http://static.jiandati.com/3fbc085-chaoxing2016-751869.png) ,作和式
,作和式![设函数[图]在[图]上有定义,在[图]内任意插入[图]个分...设函数在上有定义,在内任意插入个分点](http://static.jiandati.com/4a4b0e8-chaoxing2016-751870.png) ,其中
,其中![设函数[图]在[图]上有定义,在[图]内任意插入[图]个分...设函数在上有定义,在内任意插入个分点](http://static.jiandati.com/54b5062-chaoxing2016-751871.png) ,设
,设![设函数[图]在[图]上有定义,在[图]内任意插入[图]个分...设函数在上有定义,在内任意插入个分点](http://static.jiandati.com/31b32a5-chaoxing2016-751872.png) ,如果当
,如果当![设函数[图]在[图]上有定义,在[图]内任意插入[图]个分...设函数在上有定义,在内任意插入个分点](http://static.jiandati.com/d91fee1-chaoxing2016-751873.png) 时和式极限存在,且极限与区间
时和式极限存在,且极限与区间![设函数[图]在[图]上有定义,在[图]内任意插入[图]个分...设函数在上有定义,在内任意插入个分点](http://static.jiandati.com/a5f8d5f-chaoxing2016-751874.png) 的分法无关,则称函数
的分法无关,则称函数![设函数[图]在[图]上有定义,在[图]内任意插入[图]个分...设函数在上有定义,在内任意插入个分点](http://static.jiandati.com/1b1ed9a-chaoxing2016-751875.png) 在
在![设函数[图]在[图]上有定义,在[图]内任意插入[图]个分...设函数在上有定义,在内任意插入个分点](http://static.jiandati.com/71200aa-chaoxing2016-751876.png) 上可积.
上可积.
 更多“设函数[图]在[图]上有定义,在[图]内任意插入[图]个分...”相关的问题
更多“设函数[图]在[图]上有定义,在[图]内任意插入[图]个分...”相关的问题
第1题
设函数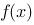 定义在
定义在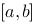 上,在
上,在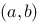 内插入
内插入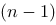 个分点,
个分点,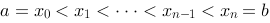 ,记此分法为
,记此分法为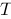 ,每一个部分区间
,每一个部分区间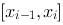 上取一点
上取一点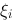 ,作和式
,作和式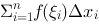 ,设
,设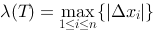 ,其中
,其中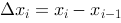 ,如果当
,如果当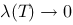 时,和式极限存在,且极限与
时,和式极限存在,且极限与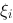 在
在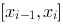 上的取法无关,则称函数
上的取法无关,则称函数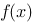 在
在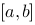 上可积.
上可积.
第2题
【说明】
散列文件的存储单位称为桶(BUCKET)。假如一个桶能存放m个记录,当桶中已有m个同义词(散列函数值相同)的记录时,存放第m+1个同义词会发生“溢出”。此时需要将第m+1个同义词存放到另一个称为“溢出桶”的桶中。相对地,称存放前m个同义词的桶为“基桶”。溢出桶和基桶大小相同,用指针链接。查找指定元素记录时,首先在基桶中查找。若找到,则成功返回,否则沿指针到溢出桶中进行查找。
例如:设散列函数为Hash(Key)=Key mod 7,记录的关键字序列为15,14,21,87,96, 293,35,24,149,19,63,16,103,77,5,153,145,356,51,68,705,453,建立的散列文件内容如图5-3所示。
.jpg)
为简化起见,散列文件的存储单位以内存单元表示。
函数InsertToHashTable(int NewElemKey)的功能是;若新元素NewElemKey正确插入散列文件中,则返回值1;否则返回值0。
采用的散列函数为Hash(NewElemKey)=NewElemKey % P,其中P为设定的基桶数目。
函数中使用的预定义符号如下:
define NULLKEY-1 /*散列桶的空闲单元标识*/
define P 7 /*散列文件中基桶的数目*/
define ITEMS 3 /*基桶和溢出桶的容量*/
typedef struet BucketNode{ /*基桶和溢出桶的类型定义*/
int KeyData[ITEMS];
struct BucketNode *Link;
}BUCKET;
BUCKET Bucket[P]; /*基桶空间定义*/
【函数5-3】
int InsertToHashTable(int NewElemKey){
/*将元素NewElemKey插入散列桶中,若插入成功则返回0,否则返回-1*/
/*设插入第一个元素前基桶的所有KeyData[],Link域已分别初始化为NULLKEY、NULL*/
int Index; /*基桶编号*/
int i,k'
BUCKET *s,*front,*t;
(1);
for(i=0;i<ITEMS;i++) /*在基桶查找空闲单元,若找到则将元素存入*/
if(Bucket[Index].KeyData[i]==NULLKEY){
Bucket[Index].KeyData[i]=NewElemKey;
break;
}
if((2))return 0;
/* 若基桶已满,则在溢出桶中查找空闲单元,若找不到则申请新的溢出桶*/
(3);
t=Bucket[Index].Link;
if(t!=NULL){ /*有溢出桶*/
while(t!=NULL){
for(k=0;k<ITEMS;k++)
if(t->KeyData[k]==NULLKEY){/* 在溢出桶链表中找到空闲单元*/
t->KeyData[k]=NewElemKey;
break;
}/*if*/
front=t;
if((4))t=t->Link;
else break;
}/*while*/
}/*if*/
if((5)){ /* 申请新溢出桶并将元素存入*/
s=(BUCKET *)malloc(sizeof(BUCKET));
if(!s)retum -1;
s->Link=NULL;
for(k=0;k<ITEMS;k++)
s->KeyData[k]=NULLKEY;
s->KeyData[0]=NewElemKey;
(6);
}/*if*/
return 0;
}/*InsertToHashTable*/
第3题
用函数编程实现在一个按升序排序的数组中查找x应插入的位置,将x插入数组中,使数组元素仍按升序排列。 提示:插入(Insertion)是数组的基本操作之一。插入法排序算法的关键在于要找到正确的插入位置,然后依次移动插入位置及其后的所有元素,腾出这个位置放入待插入的元素。插入排序的原理如图所示: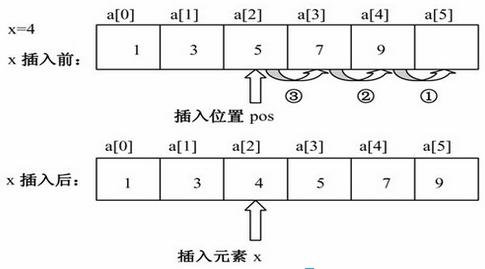 在空白处填写适当的表达式或语句,使程序完整并符合题目要求。 #include<stdio.h> #define N 20 /* 插入前数组最大元素个数 */ void Insert(int a[], int n, int x); int main() { int a[N+1]; /* 定义数组长度为插入前的数组元素个数加1 */ int x, i, n; printf("Input array size:\n"); scanf("%d", &n); /* 输入插入前数组元素个数 */ printf("Input array:\n"); for (i=0; i<n; i++) { scanf("%d", &a[i]); * 输入插入前已按升序排序的数组元素 } printf("input x:\n"); &x); 输入待插入的元素x insert(a, n, x); 插入元素x到已排序数组中 printf("after insert %d:\n", for (i="0;" printf("%4d", a[i]); 输出插入x后的数组元素 return 0; 函数功能:将x插入到一个已按升序排序的数组中 void insert(int a[], int x) i="0," pos; while (______________) 查找待插入位置 i++; pos="i;" 记录元素x应插入的数组下标位置pos _______; i--) 从尾部开始移动pos及其后所有的元素 _____________; 向后复制数组元素 a[pos]="x;" 插入元素x到位置pos> A、第30行: i < n && x > a[i] 第35行: i>= pos 第37行: a[i+1] = a[i]
在空白处填写适当的表达式或语句,使程序完整并符合题目要求。 #include<stdio.h> #define N 20 /* 插入前数组最大元素个数 */ void Insert(int a[], int n, int x); int main() { int a[N+1]; /* 定义数组长度为插入前的数组元素个数加1 */ int x, i, n; printf("Input array size:\n"); scanf("%d", &n); /* 输入插入前数组元素个数 */ printf("Input array:\n"); for (i=0; i<n; i++) { scanf("%d", &a[i]); * 输入插入前已按升序排序的数组元素 } printf("input x:\n"); &x); 输入待插入的元素x insert(a, n, x); 插入元素x到已排序数组中 printf("after insert %d:\n", for (i="0;" printf("%4d", a[i]); 输出插入x后的数组元素 return 0; 函数功能:将x插入到一个已按升序排序的数组中 void insert(int a[], int x) i="0," pos; while (______________) 查找待插入位置 i++; pos="i;" 记录元素x应插入的数组下标位置pos _______; i--) 从尾部开始移动pos及其后所有的元素 _____________; 向后复制数组元素 a[pos]="x;" 插入元素x到位置pos> A、第30行: i < n && x > a[i] 第35行: i>= pos 第37行: a[i+1] = a[i]
B、第30行: i <= n && x> a[i] 第35行: i>= 0 第37行: a[i] = a[i+1]
C、第30行: i < n || x > a[i] 第35行: i>= 1 第37行: a[i+1] = a[i]
D、第30行: i < n && x >= a[i] 第35行: i> pos 第37行: a[i] = a[i+1]
第4题
[说明]
散列文件的存储单位称为桶(BUCKET)。假如一个桶能存放m个记录,当桶中已有 m个同义词(散列函数值相同)的记录时,存放第m+1个同义词会发生“溢出”。此时需要将第m+1个同义词存放到另一个称为“溢出桶”的桶中。相对地,称存放前m个同义词的桶为“基桶”。溢出桶和基桶大小相同,用指针链接。查找指定元素记录时,首先在基桶中查找。若找到,则成功返回,否则沿指针到溢出桶中进行查找。
例如:设散列函数为Hash(Key)=Key mod 7,记录的关键字序列为15,14,21,87,97,293,35,24,149,19,63,16,103,77,5,153,145,356,51,68,705,453,建立的散列文件内容如图4-1所示。
[图4-1]
.jpg)
为简化起见,散列文件的存储单位以内存单元表示。
函数InsertToHashTable(int NewElemKey)的功能是:将元素NewEIemKey插入散列桶中,若插入成功则返回0,否则返回-1。
采用的散列函数为Hash(NewElemKey)=NewElemKey % P,其中P为设定的基桶数目。
函数中使用的预定义符号如下:
define NULLKEY -1 /*散列桶的空闲单元标识*/
define P 7 /*散列文件中基桶的数目*/
define ITEMS 3 /*基桶和溢出桶的容量*/
typedef struct BucketNode{ /*基桶和溢出桶的类型定义*/
int KcyData[ITEMS];
struct BucketNode *Link;
}BUCKET;
BUCKET Bucket[P]; /*基桶空间定义*/
[函数]
int lnsertToHashTable(int NewElemKey){
/*将元素NewElemKey插入散列桶中,若插入成功则返回0,否则返回-1*/
/*设插入第一个元素前基桶的所有KeyData[]、Link域已分别初始化为NULLKEY、
NULL*/
int Index; /*基桶编号*/
int i,k;
BUCKET *s,*front,*t;
(1) ;
for(i=0; i<ITEMS;i++)/*在基桶查找空闲单元,若找到则将元素存入*/
if(Bucket[Index].KeyData[i]=NULLKEY){
Bucket[Index].KeyData[i]=NewElemKey; break;
}
if( (2) ) return 0;
/*若基桶已满,则在溢出桶中查找空闲单元,若找不到则申请新的溢出桶*/
(3) ; t=Bucket[Index].Link;
if(t!=NULL) {/*有溢出桶*/
while (t!=NULL){
for(k=0; k<ITEMS; k++)
if(t->KeyData[k]=NULLKEY){/*在溢出桶链表中找到空闲单元*/
t->KeyData[k]=NewElemKey; break;
}/*if*/
front=t;
if( (4) )t=t->Link;
else break;
}/*while*/
}/*if*/
if( (5) ) {/*申请新溢出桶并将元素存入*/
s=(BUCKET*)malloe(sizeof(BUCKET));
if(!s) return-1;
s->Link=NULL;
for(k=0; k<ITEMS; k++)
s->KeyData[k]=NULLKEY;
s->KeyData[0]=NewElemKey;
(6) ;
}/*if*/
return 0;
}/*InsertToHashTable*/
第5题
[说明]
当一元多项式 中有许多系数为零时,可用一个单链表来存储,每个节点存储一个非零项的指受和对应系数。
中有许多系数为零时,可用一个单链表来存储,每个节点存储一个非零项的指受和对应系数。
为了便于进行运算,用带头节点的单链表存储,头节点中存储多项式中的非零项数,且各节点按指数递减顺序存储。例如:多项式8x5-2x2+7的存储结构为:

流程图图3-1用于将pC(Node结构体指针)节点按指数降序插入到多项式C(多项式POLY指针)中。
流程图中使用的符号说明如下:
(1)数据结构定义如下:
define EPSI 1e-6
struct Node{ /*多项式中的一项*/
double c; /*系数*/
int e; /*指数*/
Struct Node *next;
};
typedef struct{ /*多项式头节点*/
int n; /*多项式不为零的项数*/
struct Node *head;
}POLY;
(2)Del(POLY *C,struct Node *p)函数,若p是空指针则删除头节点,否则删除p节点的后继。
(3)fabs(double c)函数返回实数C的绝对值。
[图3-1]

(1)
第6题
阅读下列说明和C代码,回答问题1至问题 3,将解答写在答题纸的对应栏内。
【说明】
堆数据结构定义如下:


在一个堆中,若堆顶元素为最大元素,则称为大顶堆;若堆顶元素为最小元素,则称为小顶堆。堆常用完全二叉树表示,图4-1 是一个大顶堆的例子。
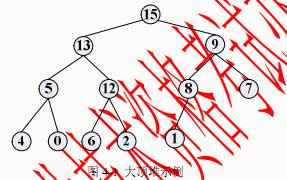
堆数据结构常用于优先队列中,以维护由一组元素构成的集合。对应于两类堆结构,优先队列也有最大优先队列和最小优先队列,其中最大优先队列采用大顶堆,最小优先队列采用小顶堆。以下考虑最大优先队列。
假设现已建好大顶堆A,且已经实现了调整堆的函数heapify(A, n, index)。
下面将C代码中需要完善的三个函数说明如下:
(1)heapMaximum(A):返回大顶堆A中的最大元素。
(2)heapExtractMax(A):去掉并返回大顶堆 A的最大元素,将最后一个元素“提前”到堆顶位置,并将剩余元素调整成大顶堆。
(3)maxHeapInsert(A, key):把元素key插入到大顶堆 A的最后位置,再将 A调整成大顶堆。
优先队列采用顺序存储方式,其存储结构定义如下:
define PARENT(i) i/2
typedef struct array{
int *int_array; //优先队列的存储空间首地址
int array_size; //优先队列的长度
int capacity; //优先队列存储空间的容量
} ARRAY;
【C代码】
(1)函数heapMaximum
int heapMaximum(ARRAY *A){ return (1) ; }
(2)函数heapExtractMax
int heapExtractMax(ARRAY *A){
int max;
max = A->int_array[0];
(2) ;
A->array_size --;
heapify(A,A->array_size,0); //将剩余元素调整成大顶堆
return max;
}
(3)函数maxHeapInsert
int maxHeapInsert(ARRAY *A,int key){
int i,*p;
if (A->array_size == A->capacity) { //存储空间的容量不够时扩充空间
p = (int*)realloc(A->int_array, A->capacity *2 * sizeof(int));
if (!p) return -1;
A->int_array = p;
A->capacity = 2 * A->capacity;
}
A->array_size ++;
i = (3) ;
while (i > 0 && (4) ){
A->int_array[i] = A->int_array[PARENT(i)];
i = PARENT(i);
}
(5) ;
return 0;
}
【问题 1】(10分)
根据以上说明和C代码,填充C代码中的空(1)~(5)。
【问题 2】(3分)
根据以上C代码,函数heapMaximum、heapExtractMax和 maxHeapInsert的时间复杂度的紧致上界分别为 (6) 、 (7) 和 (8) (用O 符号表示)。
【问题 3】(2分)
若将元素10插入到堆A =〈15, 13, 9, 5, 12, 8, 7, 4, 0, 6, 2, 1〉中,调用 maxHeapInsert函数进行操作,则新插入的元素在堆A中第 (9) 个位置(从 1 开始)。
第7题
A、ORDER BY
B、GROUP BY
C、HAVING
D、SELECT
第8题
说明:堆数据结构定义如下。对于n个元素的关键字序列(a1,a2,...,an),当且仅当满足下列关系时称其为堆:在 一个堆中,若堆顶元素为最大元素,则称为大顶堆;若堆顶元素为最小元素,则称为小顶堆。堆常用完全二叉树表示,图8.11是一个大顶堆的例子。
一个堆中,若堆顶元素为最大元素,则称为大顶堆;若堆顶元素为最小元素,则称为小顶堆。堆常用完全二叉树表示,图8.11是一个大顶堆的例子。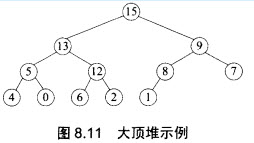 堆数据结构常用于优先队列中,以维护由一组元素构成的集合。对应于两类堆结构,优先队列也有最大优先队列和最小优先队列,其中最大优先队列采用大顶堆,最小优先队列采用小项堆。以下考虑最大优先队列。假设现已建好大顶堆A,且已经实现了调整堆的函数heapify(A,n,index)。下面将C代码中需要完善的3个函数说明如下。
堆数据结构常用于优先队列中,以维护由一组元素构成的集合。对应于两类堆结构,优先队列也有最大优先队列和最小优先队列,其中最大优先队列采用大顶堆,最小优先队列采用小项堆。以下考虑最大优先队列。假设现已建好大顶堆A,且已经实现了调整堆的函数heapify(A,n,index)。下面将C代码中需要完善的3个函数说明如下。
(1)heapMaximum(A):返回大顶堆A中的最大元素。
(2)heapExtractMax(A):去掉并返回大顶堆A的最大元素,将最后一个元素"提前"到堆顶位置,并将剩余元素调整成大顶堆。(
3)maxHeapInsert(A,key):把元素key插入到大顶堆A的最后位置,再将A调整成大顶堆。优先队列采用顺序存储方式,其存储结构定义如下: C代码:
C代码:
第9题

A.删除链表head中的所有结点
B.计算链表head中结点的个数
C.插入一个元素到链表head中
D.创建一个链表head
第10题

 客服
客服
 TOP
TOP

 警告:系统检测到您的账号存在安全风险
警告:系统检测到您的账号存在安全风险
为了保护您的账号安全,请在“上学吧”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!































