 重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
设函数![设函数[图]定义在[图]上,在[图]内插入[图]个分点,[图]...设函数定义在上,在内插入个分点,](http://static.jiandati.com/7af622d-chaoxing2016-667519.png) 定义在
定义在![设函数[图]定义在[图]上,在[图]内插入[图]个分点,[图]...设函数定义在上,在内插入个分点,](http://static.jiandati.com/545dd4d-chaoxing2016-667520.png) 上,在
上,在![设函数[图]定义在[图]上,在[图]内插入[图]个分点,[图]...设函数定义在上,在内插入个分点,](http://static.jiandati.com/047f8ce-chaoxing2016-667521.png) 内插入
内插入![设函数[图]定义在[图]上,在[图]内插入[图]个分点,[图]...设函数定义在上,在内插入个分点,](http://static.jiandati.com/90a2b66-chaoxing2016-667522.png) 个分点,
个分点,![设函数[图]定义在[图]上,在[图]内插入[图]个分点,[图]...设函数定义在上,在内插入个分点,](http://static.jiandati.com/d777fd5-chaoxing2016-667523.png) ,记此分法为
,记此分法为![设函数[图]定义在[图]上,在[图]内插入[图]个分点,[图]...设函数定义在上,在内插入个分点,](http://static.jiandati.com/ae66d0f-chaoxing2016-667524.png) ,每一个部分区间
,每一个部分区间![设函数[图]定义在[图]上,在[图]内插入[图]个分点,[图]...设函数定义在上,在内插入个分点,](http://static.jiandati.com/ee1bc67-chaoxing2016-667525.png) 上取一点
上取一点![设函数[图]定义在[图]上,在[图]内插入[图]个分点,[图]...设函数定义在上,在内插入个分点,](http://static.jiandati.com/dde58fc-chaoxing2016-667526.png) ,作和式
,作和式![设函数[图]定义在[图]上,在[图]内插入[图]个分点,[图]...设函数定义在上,在内插入个分点,](http://static.jiandati.com/6d2bbc8-chaoxing2016-667527.png) ,设
,设![设函数[图]定义在[图]上,在[图]内插入[图]个分点,[图]...设函数定义在上,在内插入个分点,](http://static.jiandati.com/ac72f21-chaoxing2016-667528.png) ,其中
,其中![设函数[图]定义在[图]上,在[图]内插入[图]个分点,[图]...设函数定义在上,在内插入个分点,](http://static.jiandati.com/f29517f-chaoxing2016-667529.png) ,如果当
,如果当![设函数[图]定义在[图]上,在[图]内插入[图]个分点,[图]...设函数定义在上,在内插入个分点,](http://static.jiandati.com/1861152-chaoxing2016-667530.png) 时,和式极限存在,且极限与
时,和式极限存在,且极限与![设函数[图]定义在[图]上,在[图]内插入[图]个分点,[图]...设函数定义在上,在内插入个分点,](http://static.jiandati.com/9adaacf-chaoxing2016-667531.png) 在
在![设函数[图]定义在[图]上,在[图]内插入[图]个分点,[图]...设函数定义在上,在内插入个分点,](http://static.jiandati.com/8e41731-chaoxing2016-667532.png) 上的取法无关,则称函数
上的取法无关,则称函数![设函数[图]定义在[图]上,在[图]内插入[图]个分点,[图]...设函数定义在上,在内插入个分点,](http://static.jiandati.com/f40eff4-chaoxing2016-667533.png) 在
在![设函数[图]定义在[图]上,在[图]内插入[图]个分点,[图]...设函数定义在上,在内插入个分点,](http://static.jiandati.com/fbfaa1a-chaoxing2016-667534.png) 上可积.
上可积.
 更多“设函数[图]定义在[图]上,在[图]内插入[图]个分点,[图]...”相关的问题
更多“设函数[图]定义在[图]上,在[图]内插入[图]个分点,[图]...”相关的问题
第1题
设函数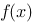 在
在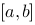 上有定义,在
上有定义,在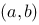 内任意插入
内任意插入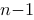 个分点,
个分点,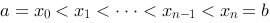 , 此分法记为
, 此分法记为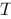 ,在每一部分区间
,在每一部分区间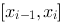 上取一点
上取一点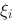 ,作和式
,作和式 ,其中
,其中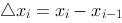 ,设
,设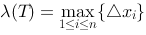 ,如果当
,如果当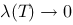 时和式极限存在,且极限与区间
时和式极限存在,且极限与区间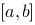 的分法无关,则称函数
的分法无关,则称函数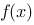 在
在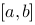 上可积.
上可积.
第2题
【说明】
散列文件的存储单位称为桶(BUCKET)。假如一个桶能存放m个记录,当桶中已有m个同义词(散列函数值相同)的记录时,存放第m+1个同义词会发生“溢出”。此时需要将第m+1个同义词存放到另一个称为“溢出桶”的桶中。相对地,称存放前m个同义词的桶为“基桶”。溢出桶和基桶大小相同,用指针链接。查找指定元素记录时,首先在基桶中查找。若找到,则成功返回,否则沿指针到溢出桶中进行查找。
例如:设散列函数为Hash(Key)=Key mod 7,记录的关键字序列为15,14,21,87,96, 293,35,24,149,19,63,16,103,77,5,153,145,356,51,68,705,453,建立的散列文件内容如图5-3所示。
.jpg)
为简化起见,散列文件的存储单位以内存单元表示。
函数InsertToHashTable(int NewElemKey)的功能是;若新元素NewElemKey正确插入散列文件中,则返回值1;否则返回值0。
采用的散列函数为Hash(NewElemKey)=NewElemKey % P,其中P为设定的基桶数目。
函数中使用的预定义符号如下:
define NULLKEY-1 /*散列桶的空闲单元标识*/
define P 7 /*散列文件中基桶的数目*/
define ITEMS 3 /*基桶和溢出桶的容量*/
typedef struet BucketNode{ /*基桶和溢出桶的类型定义*/
int KeyData[ITEMS];
struct BucketNode *Link;
}BUCKET;
BUCKET Bucket[P]; /*基桶空间定义*/
【函数5-3】
int InsertToHashTable(int NewElemKey){
/*将元素NewElemKey插入散列桶中,若插入成功则返回0,否则返回-1*/
/*设插入第一个元素前基桶的所有KeyData[],Link域已分别初始化为NULLKEY、NULL*/
int Index; /*基桶编号*/
int i,k'
BUCKET *s,*front,*t;
(1);
for(i=0;i<ITEMS;i++) /*在基桶查找空闲单元,若找到则将元素存入*/
if(Bucket[Index].KeyData[i]==NULLKEY){
Bucket[Index].KeyData[i]=NewElemKey;
break;
}
if((2))return 0;
/* 若基桶已满,则在溢出桶中查找空闲单元,若找不到则申请新的溢出桶*/
(3);
t=Bucket[Index].Link;
if(t!=NULL){ /*有溢出桶*/
while(t!=NULL){
for(k=0;k<ITEMS;k++)
if(t->KeyData[k]==NULLKEY){/* 在溢出桶链表中找到空闲单元*/
t->KeyData[k]=NewElemKey;
break;
}/*if*/
front=t;
if((4))t=t->Link;
else break;
}/*while*/
}/*if*/
if((5)){ /* 申请新溢出桶并将元素存入*/
s=(BUCKET *)malloc(sizeof(BUCKET));
if(!s)retum -1;
s->Link=NULL;
for(k=0;k<ITEMS;k++)
s->KeyData[k]=NULLKEY;
s->KeyData[0]=NewElemKey;
(6);
}/*if*/
return 0;
}/*InsertToHashTable*/
第3题
[说明]
散列文件的存储单位称为桶(BUCKET)。假如一个桶能存放m个记录,当桶中已有 m个同义词(散列函数值相同)的记录时,存放第m+1个同义词会发生“溢出”。此时需要将第m+1个同义词存放到另一个称为“溢出桶”的桶中。相对地,称存放前m个同义词的桶为“基桶”。溢出桶和基桶大小相同,用指针链接。查找指定元素记录时,首先在基桶中查找。若找到,则成功返回,否则沿指针到溢出桶中进行查找。
例如:设散列函数为Hash(Key)=Key mod 7,记录的关键字序列为15,14,21,87,97,293,35,24,149,19,63,16,103,77,5,153,145,356,51,68,705,453,建立的散列文件内容如图4-1所示。
[图4-1]
.jpg)
为简化起见,散列文件的存储单位以内存单元表示。
函数InsertToHashTable(int NewElemKey)的功能是:将元素NewEIemKey插入散列桶中,若插入成功则返回0,否则返回-1。
采用的散列函数为Hash(NewElemKey)=NewElemKey % P,其中P为设定的基桶数目。
函数中使用的预定义符号如下:
define NULLKEY -1 /*散列桶的空闲单元标识*/
define P 7 /*散列文件中基桶的数目*/
define ITEMS 3 /*基桶和溢出桶的容量*/
typedef struct BucketNode{ /*基桶和溢出桶的类型定义*/
int KcyData[ITEMS];
struct BucketNode *Link;
}BUCKET;
BUCKET Bucket[P]; /*基桶空间定义*/
[函数]
int lnsertToHashTable(int NewElemKey){
/*将元素NewElemKey插入散列桶中,若插入成功则返回0,否则返回-1*/
/*设插入第一个元素前基桶的所有KeyData[]、Link域已分别初始化为NULLKEY、
NULL*/
int Index; /*基桶编号*/
int i,k;
BUCKET *s,*front,*t;
(1) ;
for(i=0; i<ITEMS;i++)/*在基桶查找空闲单元,若找到则将元素存入*/
if(Bucket[Index].KeyData[i]=NULLKEY){
Bucket[Index].KeyData[i]=NewElemKey; break;
}
if( (2) ) return 0;
/*若基桶已满,则在溢出桶中查找空闲单元,若找不到则申请新的溢出桶*/
(3) ; t=Bucket[Index].Link;
if(t!=NULL) {/*有溢出桶*/
while (t!=NULL){
for(k=0; k<ITEMS; k++)
if(t->KeyData[k]=NULLKEY){/*在溢出桶链表中找到空闲单元*/
t->KeyData[k]=NewElemKey; break;
}/*if*/
front=t;
if( (4) )t=t->Link;
else break;
}/*while*/
}/*if*/
if( (5) ) {/*申请新溢出桶并将元素存入*/
s=(BUCKET*)malloe(sizeof(BUCKET));
if(!s) return-1;
s->Link=NULL;
for(k=0; k<ITEMS; k++)
s->KeyData[k]=NULLKEY;
s->KeyData[0]=NewElemKey;
(6) ;
}/*if*/
return 0;
}/*InsertToHashTable*/
第4题
A. 选中自变量后,可以通过插入“运动”按钮的方式,设置自变量“动画”按钮。
B. 自变量是连续变化的。
C. 缺省状态,定义自变量会自带按钮
D. 通过自变量自带按钮,可以调节自变量的变化范围。

 客服
客服
 TOP
TOP

 警告:系统检测到您的账号存在安全风险
警告:系统检测到您的账号存在安全风险
为了保护您的账号安全,请在“上学吧”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!

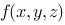 在
在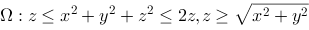 上连续,则
上连续,则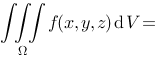
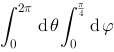
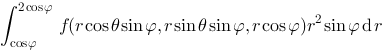 .
.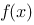 在
在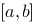 上连续,在
上连续,在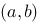 内可导,若
内可导,若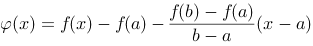 ,
,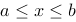 ,则至少存在一点
,则至少存在一点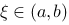 ,使得
,使得 .
.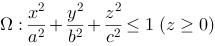 上连续,令
上连续,令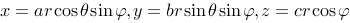 , 则
, 则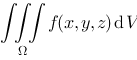
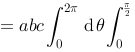
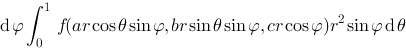 .
.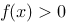 ,则方程
,则方程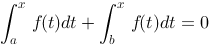 在
在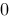
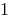
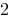
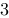
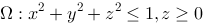 上连续,则
上连续,则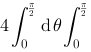

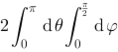
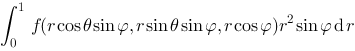

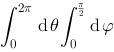
 ,则
,则 成立的
成立的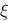 的个数为 .
的个数为 .





























