Spark是一个专为大规模数据处理而设计的快速通用的计算引擎,官方支持Scala、Java、C、Python语言
第1题
下列三个算法是关于“大规模数据集合中查找有无某些元素”问题的算法:针对一个“学生”数据表,如下示意,找出“成绩”为某一分数的所有学生。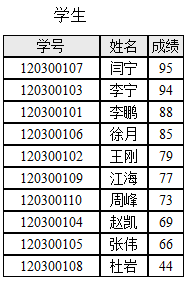 【算法A1】 Start of algorithm A1 Step 1. 从数据表的第1条记录开始,直到其最后一条记录为止,读取每一条记录,做Step 2。 Step 2. 对每一条记录,判断成绩是否等于给定的分数:如果是,则输出;如果不是,则不输出。 End of algorithm A1 【算法A2】 Start of algorithm A2 Step 1. 从数据表的第1条记录开始,直到其最后一条记录为止,读取每一条记录,做Step 2和Step 3。 Step 2. 对每一条记录,判断成绩是否等于给定的分数:如果等于,则输出;如果不等于,则不输出。 Step 3. 判断该条记录的成绩是否小于给定的分数:如果不是,则继续;否则,退出循环,算法结束。 End of algorithm A2 【算法A3】 Start of algorithm A3 Step 1. 假设数据表的最大记录数是n,待查询区间的起始记录位置Start为1,终止记录位置Finish为n; Step 2. 计算中间记录位置I = (Start+Finish)/2,读取第I条记录。 Step 3. 判断第I条记录的成绩与给定查找分数: (3.1)如果是小于关系,则调整Finish = I-1;如果Start >Finish则结束,否则继续做Step 2; (3.2)如果是大于关系,则调整Start = I+1;如果Start>Finish则结束,否则继续做Step 2; (3.3)如果是等于关系,则输出,继续读取I周围所有的成绩与给定查找条件相等的记录并输出,直到所有相等记录查询输出完毕则算法结束。 End of algorithm A3 关于算法A1, A2, A3的快慢问题,下列说法正确的是_____。
【算法A1】 Start of algorithm A1 Step 1. 从数据表的第1条记录开始,直到其最后一条记录为止,读取每一条记录,做Step 2。 Step 2. 对每一条记录,判断成绩是否等于给定的分数:如果是,则输出;如果不是,则不输出。 End of algorithm A1 【算法A2】 Start of algorithm A2 Step 1. 从数据表的第1条记录开始,直到其最后一条记录为止,读取每一条记录,做Step 2和Step 3。 Step 2. 对每一条记录,判断成绩是否等于给定的分数:如果等于,则输出;如果不等于,则不输出。 Step 3. 判断该条记录的成绩是否小于给定的分数:如果不是,则继续;否则,退出循环,算法结束。 End of algorithm A2 【算法A3】 Start of algorithm A3 Step 1. 假设数据表的最大记录数是n,待查询区间的起始记录位置Start为1,终止记录位置Finish为n; Step 2. 计算中间记录位置I = (Start+Finish)/2,读取第I条记录。 Step 3. 判断第I条记录的成绩与给定查找分数: (3.1)如果是小于关系,则调整Finish = I-1;如果Start >Finish则结束,否则继续做Step 2; (3.2)如果是大于关系,则调整Start = I+1;如果Start>Finish则结束,否则继续做Step 2; (3.3)如果是等于关系,则输出,继续读取I周围所有的成绩与给定查找条件相等的记录并输出,直到所有相等记录查询输出完毕则算法结束。 End of algorithm A3 关于算法A1, A2, A3的快慢问题,下列说法正确的是_____。
A、算法A1快于算法A2, 算法A2快于算法A3
B、算法A2快于算法A1, 算法A2快于算法A3
C、算法A3快于算法A2, 算法A2快于算法A1
D、算法A1快于算法A3, 算法A3快于算法A2
第2题
下列三个算法是关于“大规模数据集合中查找有无某些元素”问题的算法:针对一个“学生”数据表,如下示意,找出“成绩”为某一分数的所有学生。【算法A1】 Start of algorithm A1 Step 1. 从数据表的第1条记录开始,直到其最后一条记录为止,读取每一条记录,做Step 2。 Step 2. 对每一条记录,判断成绩是否等于给定的分数:如果是,则输出;如果不是,则不输出。End of algorithm A1 【算法A2】 Start of algorithm A2 Step 1. 从数据表的第1条记录开始,直到其最后一条记录为止,读取每一条记录,做Step 2和Step 3。 Step 2. 对每一条记录,判断成绩是否等于给定的分数:如果等于,则输出;如果不等于,则不输出。 Step 3. 判断该条记录的成绩是否小于给定的分数:如果不是,则继续;否则,退出循环,算法结束。 End of algorithm A2 【算法A3】 Start of algorithm A3 Step 1. 假设数据表的最大记录数是n,待查询区间的起始记录位置Start为1,终止记录位置Finish为n; Step 2. 计算中间记录位置I = (Start+Finish)/2,读取第I条记录。 Step 3. 判断第I条记录的成绩与给定查找分数: (3.1)如果是小于关系,则调整Finish = I-1;如果Start >Finish则结束,否则继续做Step 2; (3.2)如果是大于关系,则调整Start = I+1;如果Start>Finish则结束,否则继续做Step 2; (3.3)如果是等于关系,则输出,继续读取I周围所有的成绩与给定查找条件相等的记录并输出,直到所有相等记录查询输出完毕则算法结束。 End of algorithm A3针对上述三个算法,回答问题:关于三个算法的复杂性,下列说法正确的是_____。
A、算法A1和A2的时间复杂性为O(n),算法A3的时间复杂性为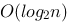
B、算法A1、A2和A3的时间复杂性都为O(n)
C、算法A1和A2的时间复杂性为O(1),算法A3的时间复杂性为O(n)
D、算法A1的时间复杂性为O(n),算法A2的时间复杂性为O(n/2),算法A3的时间复杂性为O(n/4)
第3题
下列三个算法是关于“大规模数据集合中查找有无某些元素”问题的算法:针对一个“学生”数据表,如下示意,找出“成绩”为某一分数的所有学生。【算法A1】 Start of algorithm A1 Step 1. 从数据表的第1条记录开始,直到其最后一条记录为止,读取每一条记录,做Step 2。 Step 2. 对每一条记录,判断成绩是否等于给定的分数:如果是,则输出;如果不是,则不输出。 End of algorithm A1 【算法A2】 Start of algorithm A2 Step 1. 从数据表的第1条记录开始,直到其最后一条记录为止,读取每一条记录,做Step 2和Step 3。 Step 2. 对每一条记录,判断成绩是否等于给定的分数:如果等于,则输出;如果不等于,则不输出。 Step 3. 判断该条记录的成绩是否小于给定的分数:如果不是,则继续;否则,退出循环,算法结束。 End of algorithm A2 【算法A3】 Start of algorithm A3 Step 1. 假设数据表的最大记录数是n,待查询区间的起始记录位置Start为1,终止记录位置Finish为n; Step 2. 计算中间记录位置I = (Start+Finish)/2,读取第I条记录。 Step 3. 判断第I条记录的成绩与给定查找分数: (3.1)如果是小于关系,则调整Finish = I-1;如果Start >Finish则结束,否则继续做Step 2; (3.2)如果是大于关系,则调整Start = I+1;如果Start>Finish则结束,否则继续做Step 2; (3.3)如果是等于关系,则输出,继续读取I周围所有的成绩与给定查找条件相等的记录并输出,直到所有相等记录查询输出完毕则算法结束。 End of algorithm A3 关于算法A1, A2, A3的快慢问题,下列说法正确的是_____。
A、算法A1快于算法A2, 算法A2快于算法A3
B、算法A2快于算法A1, 算法A2快于算法A3
C、算法A3快于算法A2, 算法A2快于算法A1
D、算法A1快于算法A3, 算法A3快于算法A2
第4题
A、Flink是一行一行地处理数据
B、Flink可以支持毫秒级的响应
C、Flink只能支持秒级的响应
D、Flink支持增量迭代,具有对迭代进行自动优化的功能
第6题
设计一个计算“一元二次方程”的程序# include <stdio.h> # include <math.h> int main(void) { float a, b, c; //定义一元二次方程的三个系数 char k; //用于后面判断是否要继续输入 double delta, x1, x2; /*delta用来存储b*b - 4*a*c的值;x1和x2的值分别为方程的解*/ do { //输入一元二次方程的三个系数a、b、c printf("请输入一元二次方程的三个系数, 用回车分隔:\n"); printf("a = "); scanf("%f", &a); while(getchar() != '\n'); /*容错处理, scanf后面都加上这一句, 作用是清空输入缓冲区, 以防用户乱输入*/ printf("b = "); scanf("%f", &b); while(getchar() != '\n'); printf("c = "); scanf("%f", &c); while(getchar() != '\n'); delta = b*b - 4*a*c; //判断delta的值是大于零, 等于零, 还是小于零 if (delta > 0) { x1 = (-b +sqrt(delta)) / (2*a); x2 = (-b -sqrt(delta)) / (2*a); printf("有两个解, x1 = %f, x2 = %f\n", x1, x2); } else if (0 == delta) { x1 = x2 = (-b) / (2*a); printf("有唯一解, x1 = x2 = %f\n", x1); } else { printf("无实数解\n"); } //询问是否想继续输入 printf("您想继续吗, Y想, N不想:"); scanf("%c", &k); //输入Y或者N, 表示“想”或“不想” while(getchar() != '\n'); } while (_______); return 0; } —————————————————————————————————————————— 输出结果是: 请输入一元二次方程的三个系数, 用回车分隔:a = 1b = 5c = 6有两个解, x1 = -2.000000, x2 = -3.000000您想继续吗, Y想, N不想:Y请输入一元二次方程的三个系数, 用回车分隔:a = 2b = 3c = 4无实数解您想继续吗, Y想, N不想:N
第7题
A、Scala是Spark的主要编程语言,但Spark还支持Java、Python、R作为编程语言
B、Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高
C、Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制
D、Spark的计算模式也属于MapReduce,但编程模型比Hadoop MapReduce更灵活
第8题
A、通过对决策表的每个字段进行数据分片(然后每个字段再按照记录分片),可以实现决策树重要分枝属性的选择。
B、可以对决策表的样本进行划分,并行计算每个分片数据各种属性取值对应的类别个数,从而可以合并这些数据得到某个属性在整个数据集的重要性度量。
C、决策树对大数据的处理只能采用批处理的算法。
D、决策树的分布式学习可以借助MapReduce计算框架。
第9题
A、Pig:处理大规模数据的脚本语言
B、Tez:支持DAG作业的计算框架
C、Oozie:工作流和协作服务引擎
D、Kafka:分布式发布订阅消息系统
第10题
A、Hadoop和Spark可以相互协作
B、Hadoop负责数据的存储和管理
C、Spark负责数据的计算
D、Spark要操作Hadoop中的数据,需要先启动HDFS




























