 重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
利用LOANAPP.RAW中的数据。
(i)估计第7章的计算机练习C8第(iii)部分中的方程,计算其异方差-稳健的标准误。将βwhite的95%的置信区间与非稳健的置信区间相比较。
(ii)由第(i)部分的回归计算拟合值。其中有没有哪个估计值小于0?有没有哪个估计值大于1?而这些情况对加权最小二乘估计的应用意味着什么?
 更多“利用LOANAPP.RAW中的数据。 (i)估计第7章的计算机练习C8第(iii)部分中的方程,计算其异方差-稳”相关的问题
更多“利用LOANAPP.RAW中的数据。 (i)估计第7章的计算机练习C8第(iii)部分中的方程,计算其异方差-稳”相关的问题
第1题
第2题
第3题
第4题
利用CEOSAL2.RAW中的数据估计模型
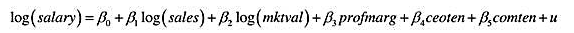
所得到的R2为R2=0.353(n=177)。若添加ceoten2和comten2后,R2=0.375。此模型中是否有函数形式误设的证据?
第5题
使用LOANAPP.RAW中的数据。
(i)有多少个观测的obrat>40,即其他债务负担超过其总收入的40%?
(ii)在第7章的计算机练习C8中,去掉obrat>40的观测,重新估计第(ii)部分中的模型。white的系数估计值和:统计量将会怎样?
(ii)βwhite看起来对所使用的样本过度敏感吗?
第6题
据吗?
(ii)计算一个异方差-稳健形式的RESET。你在第(i)部分的结论改变了吗?
第7题
利用INFMRT.RAW中1990年的数据。
(i)重新估计教材方程(9.37),但现在对哥伦比亚特区这个观测引进一个虚拟变量(记为DC)。解释DC的系数,并评论其大小和显著性。
(ii)将第(i)步所得到的估计值和标准误与教材方程(9.38)中的估计值和标准误相比较。根据这种对单个观测引进一个虚拟变量的做法,你得到什么结论?
第8题
利用TWOYEAR.RAW中的数据。
(i)变量stotal是一项标准化测试变量,可用作无法观测的能力的代理变量。求stotal的样本均值和标准差。
(ii)做jc和univ对stotal的简单回归。两个大学教育变量都与stotal统计相关吗?请解释。
(iii)在教材方程(4.17)中增加stotal,并检验二年制大专和四年制大学教育具有相同回报的假设,备择假设是四年制大学的回报更高。你的结论与4.4节中的结论有何区别?
(iv)在第(iii)部分估计的方程中增加stotal2。测试分数变量的二次项有必要吗?
(v)在第(iii)部分的方程中增加stotal·jc和stotal·univ。这两项联合显著吗?
(vi)你通过使用stotal而控制能力变量的最终模型是什么?说明你的理由。
第9题
利用401KSUBS.RAW中的数据,只使用未婚人士的数据(fsize=1)。我们关心的等式如下:
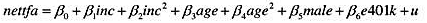
(i)利用OLS估计这个方程,按照通常形式报告结果,并解释e401k的系数。
(ii)利用布罗施-帕甘检验,使用OLS残差检验异方差性。u看上去独立于解释变量吗?
(iii)用LAD估计这个方程,并以对OLS同样的方式报告结果。解释e401k的系数。
(iv)调和第(i)部分和第(iii)部分的结论。
第10题
含了所观测到的数据,其中个人基本上是自己决定是否参加工作培训。数据集包含同一时期的数据。
(i)在数据集JTRAIN2.RAW中,男人参加工作培训的比例是多大?在JTRAIN3.RAW中的比例又是多大?你认为为什么存在这么大的差距?
(ii)利用JTRAIN2.RAW,做re78对train的简单回归。参与工作培训对真实工资的估计影响有多大?
(ii)现在,在第(ii)部分的回归中增加控制变量re74,re75,educ,age,black和hisp。工作培训对re78的估计影响变化大吗?何以至此?(提示:记得这些都是实验数据。)
(iv)利用JTRAIN3.RAW中的数据做第(ii)部分和第(iii)部分的回归,只报告train的估计系数及其:统计量。现在,控制额外因素的影响如何?为什么?
(v)定义avgre=(re74+re75)/2。求这两个数据集中的样本均值、标准差、最小值和最大值。这些数据集代表了1978年同样的总体吗?
(vi)在数据集JTRAIN2.RAW中,几乎96%的男性的avgre低于10000美元。只利用这些男性的数据,做re78对train,re74,re75,educ,age,black和hisp的回归,并报告培训估计值及其:统计量。对JTRAIN3.RAW
也只利用avgre ≤10的男性做同样的回归。就这个低收入男性子样本而言,实验数据集和非实验数据集估计的培训效应有何差别?
(vii)现在,只针对1974年和1975年失业的男性,利用每个数据集做re78对train的简单回归。培训的估计值又有何差别?
(viii)利用你前面的回归结果,试讨论在比较实验估计值和非实验估计值的背后,拥有可比较总体的潜在重要性。
第11题
使用WAGE2.RAW中的数据。
(i)在教材例9.3中,用变量KWW(“工作领域内知识”测试分数)取代IQ作为能力的代理变量。在此情形下,估计的教育回报是多少?
(ii)现在用IQ和KWW一起作为代理变量。所估计的教育回报会怎么样?
(iii)在第(ii)部分中,IQ和KWW是个别显著的吗?它们联合显著吗?
第12题
本题使用JTRAIN.RAW中的数据。
(i)考虑简单回归模型
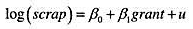
其中,scrap表示企业的废品率,grant表示是否得到工作培训津贴的一个虚拟变量。你能想到u中的无法观测因素可能会与grant相关的原因吗?
(ii)利用1988年的数据估计这个简单的回归模型。(你应该有54个观测。)得到工作培训津贴显著地降低了企业的废品率吗?
(iii)现在增加一个解释变量log(scrap87)。这将如何改变grant的估计影响?解释grant的系数。相对于单侧备择假设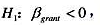 它在5%的显著性水平上统计显著吗?
它在5%的显著性水平上统计显著吗?
(iv)相对双侧备择假设,检验log(scrapg)的参数为1的虚拟假设。报告检验的P值。
(v)利用异方差-稳健标准误,重复第(iii)步和第(iv)步,并简要讨论任何明显的差异。

 客服
客服
 TOP
TOP

 警告:系统检测到您的账号存在安全风险
警告:系统检测到您的账号存在安全风险
为了保护您的账号安全,请在“上学吧”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!































