 重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
A.数据规范化是为了给重要的属性赋予更大的权重
B.数据规范化又称为数据标准化
C.数据规范化是将属性的取值范围统一
D.数据规范化是为了避免不同属性的不平等地位
 更多“下列关于数据规范化说法错误的是()。”相关的问题
更多“下列关于数据规范化说法错误的是()。”相关的问题
第1题
A、中心化将数据平移,数据之间的相对关系不变
B、中心化是将数据转换成标准正态分布
C、中心化后数据均值为0
D、中心化不一定要归一化
第2题
A.第一范式规定了关系模式中的每个分量不可再分
B.若关系模式满足第二范式,则它也满足第一范式
C.关系数据库不必满足每一个范式,只要遵循一个范式就能正常工作
D.关系模式满足巴克斯范式时,关系中所有非主属性对每个码都完全函数依赖
第3题
B、原始记录发现数据录入有误时,可以重新抄写
C、原始记录格式要规范化
D、设原始记录可用电子或电磁方式记录
第4题
B.原始记录如漏掉数据,可根据记忆补记
C.原始记录发现数据录入有误时,可以重新抄写
D.原始记录可用电子或电磁方式记录
第5题
A.第一范式规定了关系模式中的每个分量不可再分
B.若关系模式满足第二范式,则它也满足第一范式
C.关系数据库不必满足每一个范式,只要遵循一个范式就能正常工作
D.关系模式满足巴克斯范式时,关系中所有非主属性对每个码都完全函数依赖
第6题
A.第一范式规定了关系模式中的每个分量不可再分
B.若关系模式满足第二范式,则它也满足第一范式
C.关系数据库不必满足每一个范式,只要遵循一个范式就能正常工作
D.关系模式满足巴克斯范式时,关系中所有非主属性对每个码都完全函数依赖
第7题
A、经过该方法处理后的数据均值为0,标准差为1
B、可能会改变数据的分布情况
C、Python中可自定义该方法实现函数: def StandardScaler(data): data = (data - data.mean()) / data.std() return data
D、计算公式为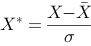
第8题
A、构建K-Means聚类模型需要对数据进行标准化
B、K-Means算法涉及空间距离计算
C、K-Means算法训练结果具有一定的随机性,所以需要多次训练
D、K-Means算法是sklearn的cluster模块中唯一涉及距离计算的聚类算法
第9题
A、关系模式是关系数据模型对具体数据的描述
B、关系模式通俗地说就是关系表的表头
C、设计关系表要遵循关系规范化要求
D、关系表跟Excel表没什么区别
第10题
A.增加派生性冗余列可以降低查询过程中的计算量
B.增加冗余列可以减少查询过程中的UNION操作
C.适当降低关系模式的规范化程度,可以减少查询过程中的JOIN操作
D.当一个表的数据量超过一定规模时,可以采用分割表的方法提高效率

 客服
客服
 TOP
TOP

 警告:系统检测到您的账号存在安全风险
警告:系统检测到您的账号存在安全风险
为了保护您的账号安全,请在“上学吧”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!































