 重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
 答案
答案
 纠错
纠错
 更多“阅读以下说明和 C 代码,填补代码中的空缺,将解答填入答题纸的对应栏内。 【说明】 对一个整数序列阅”相关的问题
更多“阅读以下说明和 C 代码,填补代码中的空缺,将解答填入答题纸的对应栏内。 【说明】 对一个整数序列阅”相关的问题
第1题
【C 代码】 include <stdio.h> int difference( int a[] ) { int t ,i ,j ,max4 ,min4; for( i=0; i<3; i++ ) { /*用简单选择排序法将 a[0] ~a[3] 按照从大到小的顺序排列* / t = i; for( j= i+1;(1); j++ ) if (a[j] >a[t]) (2); if ( t !=i ) { int temp = a[t];a[t]= a[i];a[i]= temp; } } max4=(3); min4=(4); return max4-min4; } int main () { int n,a[4]; printf("input a positive four-digi t number: ") ; scanf("%d" ,&n); while (n!=6174) { a [0] =(5); /*取n的千位数字*/ a[1] = n/100%10; /*取n的百位数字*/ a[2] = n/10%10; /*取n的十位数字*/ a[3] =(6); /*取n的个位数字*/ n = difference(a); return 0; } return 0; }
第2题
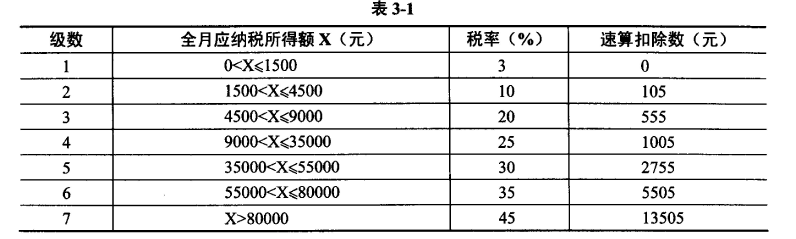 设三险一金为月工资的 19%,起征点为3500元。 例如,某人月工资为 5800元,按规定 19%缴纳三险一金,那么: 其应纳税所得额 X=5800- 5800x19%-3500=1198 元,对应税率和速算扣除数分别 为 3%和 0 元,因此,其个人所得税额为 1198X3%-0=35.94 元。
设三险一金为月工资的 19%,起征点为3500元。 例如,某人月工资为 5800元,按规定 19%缴纳三险一金,那么: 其应纳税所得额 X=5800- 5800x19%-3500=1198 元,对应税率和速算扣除数分别 为 3%和 0 元,因此,其个人所得税额为 1198X3%-0=35.94 元。【C 代码】 include <stdio.h> //起征点 define BASE 3500 //三险一金比例 define RATE 0.19 //声明函数 GetlncomeTax (1) ; int main ( ) { int id; double salary; FILE *fin,*fout; fin = fopen("Salary.dat" ,"r"); if ( (2) ) return 0; fout = fopen("IncomeTax.dat" ,"w"); if ( (3) ) return 0; while (!feof(fin)) { if (fscanf(fin,“%d%lf”, (4) )!=2) break; fprintf(fout ,“%d\t%.2lf\t%.2lf\n”,id,salary, (5) ; } fc1ose(fin); fclose(fout); return 0; } double GetlncomeTax(double salary) { double yns_sd; yns_sd = (6) - BASE; /*计算应纳税所得额*/ if (yns_sd<=0) return 0.0; else if (yns_sd<=1500) return yns_sd*0.03; else if (yns_sd<=4500) return yns_sd*0.1 - 105; else if (yns_sd<=9000) return yns_sd*0.2 - 555; else if (yns_sd<=35000) return yns_sd*0.25 - 1005; else if (yns_sd<=55000) return yns_sd*0.3 - 2755; else if (yns_sd<=80000) return yns_sd*0.35 - 5505; return yns sd*0.45 - 13505; }
第3题
 图4-1
图4-1define SUCCESS 0 define ERROR -1 typedef int Status; typedef int ElemType; 链表的结点类型定义如下: typedef struct Node{ ElemType data; struct Node *next; }Node ,*LinkList; 【C 代码】 LinkList GetListElemPtr(LinkList L ,int i) { /* L是含头结点的单链表的头指针,在该单链表中查找第i个元素结点: 若找到,则返回该元素结点的指针,否则返回NULL */ LinkList p; int k; /*用于元素结点计数*/ if (i<1 ∣∣ !L ∣∣ !L->next) return NULL; k = 1; P = L->next; / *令p指向第1个元素所在结点*/ while (p && (1) ) { /*查找第i个元素所在结点*/ (2) ; ++k; } return p; } Status DelListElem(LinkList L ,int i ,ElemType *e) { /*在含头结点的单链表L中,删除第i个元素,并由e带回其值*/ LinkList p,q; /*令p指向第i个元素的前驱结点*/ if (i==1) (3) ; else p = GetListElemPtr(L ,i-1); if (!p ∣∣ !p->next) return ERROR; /*不存在第i个元素*/ q = (4) ; /*令q指向待删除的结点*/ p->next = q->next; /*从链表中删除结点*/ (5) ; /*通过参数e带回被删除结点的数据*/ free(q); return SUCCESS; }
第4题
【说明】 某文本文件中保存了若干个日期数据,格式如下(年/月/日): 2005/12/1 2013/2/29 1997/10/11 1980/5/15 .... 但是其中有些日期是非法的,例如2013/2/29是非法日期,闰年(即能被400整除或者能被4整除而不能被100整除的年份)的2月份有29天,2013年不是闰年。现要求将其中自1985/1/1开始、至2010/12/31结束的合法日期挑选出来并输出。 下面的C代码用于完成上述要求。 【C代码】 include <stdio.h> typedef struct{ int year, month, day;/* 年,月,日*/ }DATE; int isLeap Year(int y) /*判断y表示的年份是否为闰年,是则返回1,否则返回0*/ { return((y%4==0 && y%100!=0)Il(y%400==0)); } int isLegal(DATE date) /*判断date表示的日期是否合法,是则返回1,否则返回0*/ { int y=date.year,m= date.month,d=date.day; if (y<1985 II y>2010 II m<1 II m>12 II d<l II d>31) return 0; if((m==4 ll m==6 ll m==9 II m==11)&& (1) ) return 0; If(m==2){ if(isLeap Year(y)&& (2) ) return 1; 。 else if (d>28) return 0; } return 1; } Int Lteq(DATE d1,DATE d2) /*比较日期d1和d2,若d1在d2之前或相同则返回1,否则返回0*/ { Long t1,t2; t1=d1.year*10000+d1.month*100+d1.day; t2=d2.year*10000+d2.month*100+d2.day; if( (3) ) return 1; else return 0; } int main() { DATE date,start={1985,1,1},end={2010,12,30}; FILE*fp; fp=fopen(“d.txt”,”r”); If( (4) ) return-1; while(!feof(fp)){ if(fscanf(fp,”%d%d%d”,&date.year,&date.month,&date.day)!=3) break; if( (5) ) /*判断是否为非法日期 */ continue; if( (6) ) /*调用Lteq判断是否在起至日期之间*/ printf(“%d%d%d\n”,date.year,date.month,date.day); } fclose(fp); Return 0; }
第5题
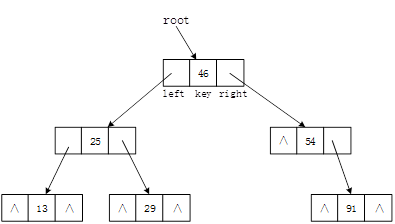 设二叉查找树采用二叉链表存储,结点类型定义如下: typedef int KeyType; typedef struct BSTNode{ KeyType key; struct BSTNode *left,*right; }BSTNode,*BSTree; 图4-1(g)所示二叉查找树的二叉链表表示如图4-2所示。图4-2 函数int InsertBST(BSTree *rootptr,KeyType kword)功能是将关键码kword插入到由rootptr指示出根结点的二叉查找树中,若插入成功,函数返回1,否则返回0。
设二叉查找树采用二叉链表存储,结点类型定义如下: typedef int KeyType; typedef struct BSTNode{ KeyType key; struct BSTNode *left,*right; }BSTNode,*BSTree; 图4-1(g)所示二叉查找树的二叉链表表示如图4-2所示。图4-2 函数int InsertBST(BSTree *rootptr,KeyType kword)功能是将关键码kword插入到由rootptr指示出根结点的二叉查找树中,若插入成功,函数返回1,否则返回0。【C代码】 int lnsertBST(BSTree*rootptr,KeyType kword) /*在二叉查找树中插入一个键值为kword的结点,若插入成功返回1,否则返回0; *rootptr为二叉查找树根结点的指针 */ { BSTree p,father; (1) ; /*将father初始化为空指针*/ p=*rootptr; /*p指示二叉查找树的根节点*/ while(p&& (2) ){ /*在二叉查找树中查找键值kword的结点*/ father=p; if(kword<p->key) p=p->left; else p=p->right; } if( (3) )return 0; /*二叉查找树中已包含键值kword,插入失败*/ p=(BSTree)malloc( (4) ); /*创建新结点用来保存键值kword*/ If(!p)return 0; /*创建新结点失败*/ p->key=kword; p->left=NULL; p->right=NULL; If(!father) (5) =p; /*二叉查找树为空树时新结点作为树根插入*/ else if(kword<father->key) (6) ; /*作为左孩子结点插入*/ else (7) ; /*作右孩子结点插入*/ return 1; }/*InsertBST*/
第6题
【C 代码】 include < stdio.h> void quicksort(int a[] ,int n) { int i ,j; int pivot = a[0]; //设置基准值 i =0; j = n-l; while (i< j) { while (i<j &&(1)) j-- //大于基准值者保持在原位置 if (i<j) { a[i]=a[j]; i++;} while (i,j &&(2)) i++; //不大于基准值者保持在原位置 if (i<j) { a[j]=a[i]; j--;} } a[i] = pivot; //基准元素归位 if ( i>1) (3) ; //递归地对左子序列进行快速排序 if ( n-i-1>1 ) (4) ; //递归地对右子序列进行快速排序 } int main () { int i,arr[ ] = {23,56,9,75,18,42,11,67}; quicksort ( (5) ); //调用 quicksort 对数组 arr[ ]进行排序 for( i=0; i<sizeof(arr) /sizeof(int); i++ ) printf(" %d\t" ,arr[i]) ; return 0; }
第7题
【说明1】 递归函数is_elem(char ch, char *set)的功能是判断ch中的字符是否在set表示的字符集合中,若是,则返回1,否则返回0。 【C代码1】 int is_elem (char ch ,char*set) { If(*set==‘\0’) return 0; else If( (1) ) return 1; else return is_elem( (2) ) } 【说明2】 函数char*combine(char* setA,char *setB)的功能是将字符集合A(元素互异,由setA表示)和字符集合B(元素互异,由setB表示)合并,并返回合并后的字符集合。 【C代码2】 char*combine(char *setA, char*setB) { int i,lenA, lenB, lenC; lenA=strlen(setA); lenB=strlen(setB); char*setC=(char*)malloc(lenA+lenB+1); if(!setC) return NULL; strncpy(setC,setA,lenA); //将setA的前lenA个字符复制后存入setC lenC= (3) ; for(i=0;i<lenB;i++) if( (4) ) //调用is_elem判断字符是否在setA中 setC[lenC++]=setB[i]; (5) =‘/0’; //设置合并后字符集的结尾标识 return setC; }
第8题
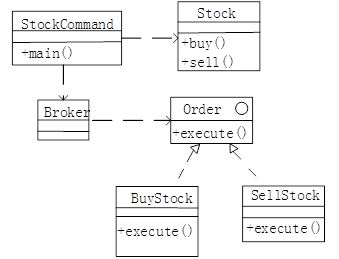 图5-1 类图
图5-1 类图【C++代码】 include <iostream> include <string> include <vector> using namespace std; class Stock { private: string name; int quantity; public: Stock(string name ,int quantity) { this->name= name;this->quantity = quantity; } void buy() { cout<<" [买进]股票名称: "<< name << ",数量: "<< quantity << endl;} void sell() { cout<<" [卖出]股票名称: " << name << ",数量:"<< quantity <<endl; } }; class Order { public: virtual void execute() = 0; }; classBuyStock: (1) { private: Stock* stock; public: BuyStock(Stock* stock) { (2) = stock; } void execute() { stock->buy () ; } }; //类SellStock的实现与BuyStock类似,此处略 c1ass Broker { private: vector < Order*> orderList; pub1ic: void takeOrder( (3) order) { orderList.push_back(order);} void p1aceOrders() { for (inti=O; i<orderList.size(); i++) { (4) -> execute () ; } orderList.c1ear(); } }; c1ass StockCommand { pub1ic: void main () { Stock* aStock = new Stock("股票 A" ,10); Stock* bStock = new Stock("股票 B" ,20); Order* buyStockOrder = new BuyStock(aStock); Order* se11StockOrder = new Se11Stock(bStock); Broker* broker = new Broker(); broker->takeOrder(buyStockOrder); broker->takeOrder(se11StockOrder); broker-> (5) () ; } }; int main() { StockCommand* stockCommand = new StockCommand(); stockCommand->main(); de1ete stockCommand; }
第9题
 图6-1
图6-1【C++代码】 include<iostream> include<string> using namespace std; class Customer{ protected: string name; public: ( 1 ) boll isNil()=0; ( 2 ) string getName()=0; ﹜; class RealCustomer ( 3 ){ Public: realCustomer(string name){this->name=name;﹜ bool isNil(){ return false; ﹜ string getName(){ return name; ﹜ ﹜; class NullCustomer ( 4 ) { public: bool isNil(){ return true; ﹜ string getName(){ return 〝Not Available in Customer Database〞; ﹜ ﹜; class Customerfactory{ public: string names[3]={〝rob〞, 〝Joe〞,〝Julie〞﹜; public: Customer*getCustomer(string name){ for (int i=0;i<3;i++){ if (names[i].( 5 ) ){ return new realCustomer(name); ﹜ ﹜ return ( 6 ); ﹜ ﹜; class CRM{ public: void getCustomer(){ Customerfactory*( 7 ); Customer*customer1=cf->getCustomer(〝Rob〞); Customer*customer2=cf->getCustomer(〝Bob〞); Customer*customer3=cf->getCustomer(〝Julie〞); Customer*customer4=cf->getCustomer(〝Laura〞); cout<<〝Customers〞<<endl; cout<<Customer1->getName()<<endl; delete customer1; cout<<Customer2->getName()<<endl; delete customer2; cout<<Customer3->getName()<<endl; delete customer3; cout<<Customer4->getName()<<endl; delete customer4; delete cf; ﹜ ﹜; int main(){ CRM*crs=new CRM(); crs->getCustomer(); delete crs; return 0; ﹜ /*程序输出为: Customers rob Not Available in Customer Database Julie Not Available in Customer Database */
第10题
 图 4-1 合并前的两个链表示意图
图 4-1 合并前的两个链表示意图 图 4-2 合并后所得链表示意图
图 4-2 合并后所得链表示意图设链表结点类型定义如下: typedef struct Node{ int data; struct Node *next; }Node ,*LinkList; 【C 函数】 LinkList Combine(LinkList La ,LinkList Lb) { //La 和 Lb 为含头结点且元素呈递减排列的单链表的头指针 //函数返回值是将 La 和 Lb 合并所得单链表的头指针 //且合并所得链表的元素值呈递增(或非递减)方式排列 (1) Lc ,tp ,pa ,pb;; //Lc 为结果链表的头指针 ,其他为临时指针 if (!La) return NULL; pa = La->next; //pa 指向 La 链表的第一个元素结点 if (!La) return NULL; pa = La->next; //pb 指向 Lb 链表的第一个元素结点 Lc = La; //取 La 链表的头结点为合并所得链表的头结点 Lc->next = NULL; while ( (2) ){ //pa 和 pb 所指结点均存在(即两个链表都没有到达表尾) //令tp指向 pa 和 pb 所指结点中的较大者 if (pa->data > pb->data) { tp = pa; pa = pa->next; } else{ tp = pb; pb = pb->next; } (3) = Lc->next; //tp 所指结点插入 Lc 链表的头结点之后 Lc->next = (4) ; } tp = (pa)? pa : pb; //设置 tp 为剩余结点所形成链表的头指针 //将剩余的结点合并入结果链表中, pa 作为临时指针使用 while (tp) { pa = tp->next; tp->next = Lc->next; Lc->next = tp; (5) ; } return Lc; }

 客服
客服
 TOP
TOP

 警告:系统检测到您的账号存在安全风险
警告:系统检测到您的账号存在安全风险
为了保护您的账号安全,请在“上学吧”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!































