 重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
阅读下列函数说明和C代码,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】
函数void rcr(int a[],int n,int k)的功能是:将数组a中的元素a[0]~a[n-1]循环向右平移k个位置。
为了达到总移动次数不超过n的要求,每个元素都必须只经过一次移动到达目标位置。在函数rcr中用如下算法实现:首先备份a[0]的值,然后计算应移动到a[0]的元素的下标p,并将a[p]的值移至a[0];接着计算应移动到a[p]的元素的下标q,并将a[q]的值移至a[p];依次类推,直到将a[0]的备份值移到正确位置。
若此时移动到位的元素个数已经为n,则结束;否则,再备份a[1]的值,然后计算应移动到a[1]的元素的下标p,并将a[p]的值移至a[1];接着计算应移动到a[p]的元素的下标q,并将a[q]的值移至a[p];依次类推,直到将a[1]的备份值移到正确位置。
若此时移动到位的元素个数已经为n,则结束;否则,从a[2]开始,重复上述过程,直至将所有的元素都移动到目标位置时为止。
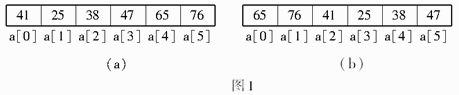
例如,数组a中的6个元素如图1(a)所示,循环向右平移两个位置后元素的排列情况如图1(b)所示。
【函数】
void rcr(int a[],int n,int k)
{int i,j,t,temp,count;
count=0;/*记录移动元素的次数*/
k=k%n;
if((1) ){/*若k是n的倍数,则元素无须移动;否则,每个元素都要移动*/
i=0;
while(count<n){
j=i;t=i;
temp=a[i];/*备份a[i]的值*/
/*移动相关元素,直到计算出a[i]应移动到的目标位置*/
while((j= (2) )!=i){
a[t]=a[j];
t= (3) ;
count++;
}
(4) =temp;count++;
(5) ;
}
}
}
 更多“阅读下列函数说明和C代码,将应填入(n)处的字句写在答题纸的对应栏内。【说明】函数void rcr(int a[]”相关的问题
更多“阅读下列函数说明和C代码,将应填入(n)处的字句写在答题纸的对应栏内。【说明】函数void rcr(int a[]”相关的问题
第1题
●试题一
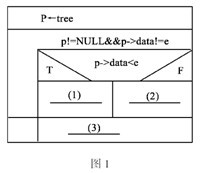
阅读下列说明和流程图,将应填入(n)的语句写在答题纸的对应栏内。
【流程图说明】
下面的流程(如图1所示)用N-S盒图形式描述了在一棵二叉树排序中查找元素的过程,节点有3个成员:data,left和right。其查找的方法是:首先与树的根节点的元素值进行比较:若相等则找到,返回此结点的地址;若要查找的元素小于根节点的元素值,则指针指向此结点的左子树,继续查找;若要查找的元素大于根节点的元素值,则指针指向此结点的右子树,继续查找。直到指针为空,表示此树中不存在所要查找的元素。
【算法说明】
【流程图】
将上题的排序二叉树中查找元素的过程用递归的方法实现。其中NODE是自定义类型:
typedef struct node{
int data;
struct node*left;
struct node*right;
}NODE;
【算法】
NODE*SearchSortTree(NODE*tree,int e)
{
if(tree!=NULL)
{
if(tree->data<e)
(4) ;∥小于查找左子树
else if(tree->data<e)
(5) ;∥大于查找左子树
else return tree;
}
return tree;
}
第2题
试题三 (共15 分 )
阅读以下说明和C 函数,将应填入 (n) 处的字句写在答题纸的对应栏内。
【说明】
基于管理的需要,每本正式出版的图书都有一个 ISBN 号。例如,某图书的 ISBN号为“978-7-5606-2348-1”。
ISBN 号由 13 位数字组成:前三位数字代表该出版物是图书(前缀号),中间的 9个数字分为三组,分别表示组号、出版者号和书名号,最后一个数字是校验码。其中,前缀号由国际EAN提供,已经采用的前缀号为978和979;组号用以区别出版者国家、地区或者语言区,其长度可为1~5位;出版者号为各出版者的代码,其长度与出版者的计划出书量直接相关;书名号代表该出版者该出版物的特定版次;校验码采用模10加权的算法计算得出。
校验码的计算方法如下:
第一步:前 12 位数字中的奇数位数字用 1 相乘,偶数位数字用 3 相乘(位编号从左到右依次为13到2);
第二步:将各乘积相加,求出总和S;
第三步:将总和S 除以10,得出余数R;
第四步:将10减去余数R后即为校验码V。若相减后的数值为10,则校验码为0。
例如,对于ISBN 号“978-7-5606-2348-1”,其校验码为1,计算过程为:
S=9×1+7×3+8×1+7×3+5×1+6×3+0×1+6×3+2×1+3×3+4×1+8×3=139
R = 139 mod 10 = 9
V = 10 – 9 = 1
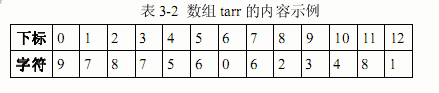
函数check(char code[])用来检查保存在code中的一个ISBN号的校验码是否正确,若正确则返回 true,否则返回 false。例如,ISBN 号“978-7-5606-2348-1”在 code 中的存储布局如表3-1所示(书号的各组成部分之间用“-”分隔):

在函数check(char code[])中,先将13位ISBN号放在整型数组元素tarr[0]~tarr[12]中(如表3-2 所示,对应 ISBN 号的位13~位 1),由 tarr[0]~tarr[11]计算出校验码放入变量V,再进行判断。
【 C 函数 】
bool check(char code[])
{
int i, k = 0;
int S = 0, temp = 0;
int V;
int tarr[13] = {0};
if (strlen(code) < 17) return false;
for( i=0; i<17; i++ ) /* 将13位ISBN 号存入tarr */
if ( code[i]!= '-' )
tarr[ (1) ] = code[i] - '0' ;
for( i=0; (2) ; i++ ) {
if ( i%2 )
S += (3) ;
else
S += (4) ;
}
V = ( (5) == 0 )? 0 : 10 - S %10;
if ( tarr[12] == V)
return true;
return false;
}
第3题
试题一(共15 分 )
阅读以下说明和流程图,将应填入 (n) 处的字句写在答题纸的对应栏内。
【 说明 】
下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。
设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在“aaaa”中只出现两次“aa”。
该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i 为字符串 A 中当前正在进行比较的动态子串首字符的下标,j为字符串B 的下标,k为指定关键词出现的次数。

第4题
阅读以下说明和Java程序,填补代码中的空缺(1)~(6),将解答填入答题纸的
对应栏内。
【说明】
很多依托扑克牌进行的游戏都要先洗牌。下面的Java代码运行时先生成一副扑克
牌,洗牌后再按顺序打印每张牌的点数和花色。
【Java代码】


第5题
阅读下列说明、c++代码和运行结果,填补代码中的空缺(1)~(6),将解答填入
答题纸的对应栏内。
【说明】
很多依托扑克牌进行的游戏都要先洗牌。下面的c++程序运行时先生成一副扑克牌,
洗牌后再按顺序打印每张牌的点数和花色。
【c++代码】
inciude <iostream>
4Finclude <stdlib. h>
include <ctime>
inciude <aigorithm>
include <string>
Using namespace std
Const string Rank[13]={”A”,”2”,”3”,”4“,“5”,”6,”’“7”8“,9”,”10,”J”,
”Q”,”K”}j//扑克牌点数



第6题
阅读以下说明和C函数,填补代码中的空缺(1)~(6),将解答填入答题纸的对
应栏内。
【说明】
二叉树的宽度定义为含有结点数最多的那一层上的结点数。函数GetWidth()用于求
二叉树的宽度。其思路是根据树的高度设置一个数组counter[]. counter[i]存放第i层上
的结点数,并按照层次顺序来遍历二叉树中的结点,在此过程中可获得每个结点的层次
值,最后从countler[]中取出最大的元素就是树的宽度。
按照层次顺序遍历二叉树的实现方法是借助一个队列,按访问结点的先后顺序来记
录结点,离根结点越近的结点越先进入队列,具体处理过程为;先令根结点及其层次号
(为1)进入初始为空的队列,然后在队列非空的情况下,取出队头所指示的结点及其层
次号,然后将该结点的左子树根结点及层次号八队列(若左子树存在),其次将该结点的
右子树根结点及层次号八队列(若右子树存在),然后再取队头,重复该过程直至完成
遍历。
设二叉树采用二叉链表存储,结点类型定义如下:
typedef struct BTNode{
TElemType data;
struct BTNode *left. *right
} BTNode , *BiTree _
队列元素的类型定义如下
typedef struct {
BTNode *ptr;
int LevelNumber
) QElemType;
【C函数】
int GetWidth (BiTree root)
{
QUEUE Q;
QElemType a, b;
int width.height = GetHeight(root);
int i, *counter =(lnt*) calloc (helght+l. sizeof (int));
if ( 1) return -1; /*申请空间失败*/
If(!root ) return -0; /*空树的宽度为0*/
if ( 1) return -1 /*初始化队列失败时返回*/
A.ptr=root; a.leveinumber=1;
If(!Enqueue(&Q,a)) return-1; /*元素入队列操作失败时返回*/
while (!isEmpty(Q》{
if( (3) )return -1; /*出队列操作失败时返回*/
Counter[b.LevelNumber]++;/*对层号为b.LevelNumber的结点计数*/
if(bNaNr=>left){/*若左子树存在,则左于树根结点及其层次号入队*/
aNaNr =bNaNr=>left;
a.LevelNurnber =(4) ;
If(!EnQueue (&Q,a))return -1;
}
if( bNaNr=>right){/*若右子树存在,则右子树根结点及其层次号入队*/
a.ptr= bNaNr->right;
a LevelNumber (5) i
If(!EnQueue (&Q,a))return -1
}
}
width= counter[1];
For(i=1; i<height+1;i++1) /*求counter[ ]中的最大值*/
If(6) width =counter[i];
Free(counter);
Return width;
}
第7题
阅读以下说明和C函数,填补函数代码中的空缺(1)~(5),将解答填入答题纸
的对应栏内。
【说明】
队列是一种常用的数据结构,其特点是先入先出,即元素的插入在表头、删除在表
尾进行。下面采用顺序存储方式实现队列,即利用一组地址连续的存储单元存放队列元
素,同时通过模运算将存储空间看作一个环状结构(称为循环队列)。
设循环队列的存储空间容量为MAXQSIZE,并在其类型定义中设置base、rear和
lengtb三个域变量,其中’base为队列空间的首地址,rear为队尾元素的指针,length表
示队列的长度。
define maxqstze 100
typedef struct {
QElemType *base; /*循环队列的存储空间首地址*/
int rear; /*队尾元素索引*/
int length; /*队列的长度*/
) SqQueue;
例如,容量为8的循环队列如图3-1所示,初始时创建的空队列如图3一l(a)所示
经过一系列的入队、出队操作后,队列的状态如图3-1 (b)所示(队列长度为3)。
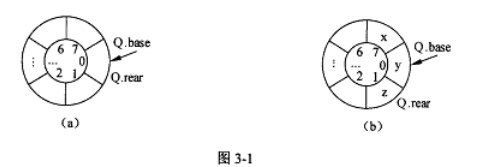
下面的C函数1、C函数2和C函数3用于实现队列的创建、插入和删除操作,请
完善这些代码。
【C函数1】创建一个空的循环队列。
int initQueue (SqQueue *Q)
/*创建容量为MAXQSIZE的空队列,若成功则返回1;否则返回0*/
{ Q->base = (QElemType*) malloc(MAXQSIZE* (1) )
if (!Q=>base) return 0;。;
Q->length=O;
Q-’rear =O:
Return 1;
} /*InitQueue*/
【c函数2】元素插入循环队列。
int EnQueue(sqQueue *Q. QElemType e)/*元素e入队,若成功则返回1;否则返回0*/
{if ( Q->length>=MAXQSIZE) return 0.;
Q->rear=(2);
Q->base [Q->rear]=e;
(3) ;
Return 1
) /*EnQUeue*/
【c函数3】元素出循环队列。
int DeQueue (SqQueue *Q. QElemType *e)
/*若队列不空,则删除队头元素,由参数e带回其值并返回1;否则返回O*/
{1f‘(4),return 0;
*e =O->base[ (Q=>rear - Q->length+I+MAXQSTZE) %MAXQSIZE]
(5) ;
returnl;
} /*DeQueue*/
第8题
阅读以下说明和C函数,填补代码中的空缺(1)~(5),将解答填入答题纸的对
应栏内。
【说明】
函数removeDuplicates(char *str)的功能是移除给定字符串中的重复字符,使每种字
符仅保留一个,其方法是:对原字符串逐个字符进行扫描,遇到重复出现的字符时,设
置标志,并将其后的非重复字符前移。例如,若str指向的字符串为“aaabbbbscbsss”,
则函数运行后该字符串为“abse”。
【c代码】
void removeDuplicates (char *str)
int i,len = strlen (str); /*求字符串长度*/
If( (l) )return;/*空串或长度为1的字符串无需处理*l
for(i=0;i<len;i++) {
Int flag =O; /*字符是否重复标志*/
int m:
for(m =( 2 ); m<len; m++){
if(str[i]==str[m] ) {
__(3)_;break;
}
}
if (flag){
Int n,idx = m;
/*字符串第idx字符之后、与str [i]不同的字符向前移*/
For( n=idx+l; n<len. n++)
if ( str[n]!= str[i]) {
str[idx]= str[n]; (4);
}
Str[(5)]=\0; /* 设置字符串结束标志*/
}
}
}
第9题
?????? 阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入答题纸的
对应栏内。
【说明】
本流程图旨在统计一本电子书中各个关键词出现的次数。假设已经对该书从头到尾
依次分离出各个关键词{A(i)li=l,…,n}(n>1)}.其中包含了很多重复项,经下面的流程
处理后,从中挑选出所有不同的关键词共m个{K(j)[j=l,…,m},而每个关键词K(j)出现的次数为NK(j).j=l,…,m。
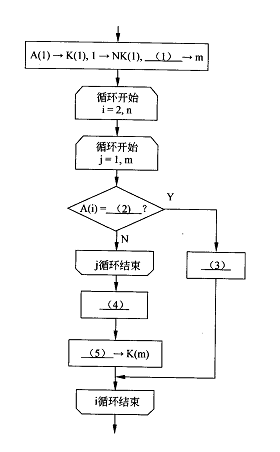
??????
第10题
n
A.reading
B.writing
C.executing
D.protecting

 客服
客服
 TOP
TOP

 警告:系统检测到您的账号存在安全风险
警告:系统检测到您的账号存在安全风险
为了保护您的账号安全,请在“上学吧”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!































